Siguiente: Análisis para el diseño Subir: Implementación de un cluster Anterior: Antecedentes
Subsecciones
- Cómputo científico
- Cluster
- Tipos y modelos de clusters
- OpenMosix como un cluster de alto desempeño y balanceo de carga
Conceptos básicos de cómputo científico y clusters
En este capítulo se tratan algunos de los conceptos fundamentales detrás del cómputo con clusters, conceptos
básicos implicados en cómputo científico, optimización de programas y algunos de tecnologías de red básicos.
Esto permite al lector trabajar con un vocabulario común cuando se comience con el tema del diseño, instalación
y configuración del cluster.
Cómputo científico
Cómputo científico:
Se entiende por cómputo científico el desarrollo y traducción en términos de tecnología de cómputo para procesar modelos computacionales, cuya finalidad es resolver problemas complejos de ciencia e ingeniería
![[*]](footnote.png) .
.
El cómputo científico usa como parte principal la modelación matemática y/o computacional. Cuando se
resuelve un problema complejo, mediante el uso de la computadora, también se le denomina experimentación numérica, la cual se considera otra rama para aprender y obtener información nueva, que se suma a las otras metodologías tradicionales: teoría y experimentación.
Cluster
Un cluster es un arreglo de computadoras conectadas por una red para trabajar en cierto gran problema que pueda
ser resuelto en pequeños pedazos [HDavid00].
Las características principales de un cluster [MCatalan04] son:
 Un cluster consta de 2 o más nodos.
Un cluster consta de 2 o más nodos.
 Los nodos del cluster están conectados entre sí por al menos un canal de comunicación.
Los nodos del cluster están conectados entre sí por al menos un canal de comunicación.
 Los clusters necesitan software de control especializado.
Los clusters necesitan software de control especializado.
Otro concepto importante es clustering, que se refiere a la técnica que permite combinar múltiples
sistemas para trabajar en conjunto, y que se comporten como un recurso informático unificado. Implica proveer
niveles de disponibilidad y escalabilidad de un sistema al menor costo.
Conceptos básicos
Alto rendimiento: Gran demanda de procesamiento de datos en procesadores, memoria y otros recursos de hardware,
donde la comunicación entre ellos es rápida.
Balanceo de carga:
Lo ideal en el procesamiento paralelo es que cada procesador realice la misma cantidad de trabajo, donde además se espera
que los procesadores trabajen al mismo tiempo. La meta del balanceo de carga es minimizar el tiempo de espera de los procesadores en los puntos de sincronización.
Compilador:
Un compilador es un programa que traduce otro programa escrito en un lenguaje de programación llamado código fuente,
en un programa equivalente al lenguaje de computadora llamado ejecutable ó binario.
Computadora vectorial:
Posee un conjunto de unidades funcionales utilizados para procesar vectores eficientemente. Contiene registros vectoriales para operar sobre ellos en un solo ciclo de reloj.
Computadora paralela: Máquina con dos o más procesadores que pueden trabajar simultánea y/o coordinadamente.
Estas son de dos tipos: las MIMD donde cada procesador puede ejecutar diferentes instrucciones sobre diferentes datos, y las
SIMD donde los procesadores ejecutan las mismas instrucciones pero con diferentes datos, como se explicara en la siguiente sección.
Eficiencia:
Es la relación entre el costo computacional y el funcionamiento del cluster; y lo que indica es qué tan eficiente se está utilizando el hardware y se expresa de la siguiente forma:
![]() ; donde
; donde ![]() es la eficiencia,
es la eficiencia,![]() es el numero de procesadores,
es el numero de procesadores, ![]() es el tiempo en que tarda en procesar un programa en particular en un procesador,
es el tiempo en que tarda en procesar un programa en particular en un procesador,
![]() es el tiempo en que tarda en procesar un programa en particular en n procesadores.
es el tiempo en que tarda en procesar un programa en particular en n procesadores.
Escalabilidad:
Generalmente se mide la eficiencia de un problema, utilizando un tamaño y un número
de procesadores fijo, pero esto es insuficiente, pues los resultados serán diferentes cuando se aumente
o disminuya el tamaño del problema y el número de procesadores. Esto es, existe un problema de
escalabilidad.
Cuando se aumenta el número de procesadores para el mismo tamaño del problema, la
sobrecarga debido al paralelismo (comunicaciones, desbalanceo de carga), aumenta y similarmente
podemos tener casos en donde el tamaño del problema es muy pequeño para tener una evaluación real
del problema sobre cierta máquina.
Flops:
Un flop es utilizado para medir operaciones de punto flotante por segundo. Es una medida de la velocidad del
procesamiento numérico del procesador. Se utilizan en unidades de millones de flops (MegaFlops), Miles de Millones de flops (GigaFlops), etc.
Kernel:
El kernel, también conocido como núcleo; es la parte fundamental de un sistema operativo. Es el software responsable
de facilitar a los distintos programas acceso seguro al hardware de la computadora.
Memoria compartida:
En una máquina paralela existe una sola memoria que puede ser accedida por todos los procesadores.
Memoria distribuida:
Cada uno de los procesadores de un multiprocesador tiene asociado a él una unidad de memoria.
Nodo:
Se refiere a una computadora sola que contiene recursos específicos, tales como memoria,
interfaces de red, uno o más CPU, etc.
Paralelismo:
Consiste en el procesamiento de una serie de instrucciones de programa que son ejecutables por múltiples procesadores
que trabajan de manera independiente [MCatalan04]
.
Existen dos formas conocidas de hacer paralelismo: una es en hardware y otra en software. Por hardware depende de la tecnología de cómputo y la de software se refiere a la habilidad del usuario para encontrar áreas bien definidas del problema que se desea resolver, de tal forma que éste pueda ser dividido en partes que serán distribuidas entre los nodos del cluster.
Proceso:
Un proceso es básicamente un programa en ejecución. Cada proceso tiene asociado un espacio de direcciones, es decir una
lista de posiciones de memoria desde algún mínimo hasta algún máximo que el proceso puede leer y escribir [ATanenbaum03].
Rendimiento:
Es la efectividad del desempeño de una computadora sobre una aplicación o prueba de rendimiento (benchmark)
en particular. En las mediciones de rendimiento están involucrados velocidad, costo y eficiencia.
Speedup(velocidad):
Se define como el tiempo que tarda en ejecutarse el mismo programa en un solo procesador, dividido entre el tiempo que
toma ejecutarse el mismo programa en ![]() procesadores.
procesadores.
![]() .
.
Donde ![]() es el speedup,
es el speedup, ![]() es el tiempo de ejecución en un procesador y
es el tiempo de ejecución en un procesador y ![]() el tiempo de ejecución en
el tiempo de ejecución en ![]() procesadores.
procesadores.
En un problema que es completamente paralelo, el valor del speedup debe ir incrementando linealmente con el valor de ![]() ,
sin embargo en muchos problemas donde el balanceo de carga no es perfecto y la comunicación entre procesos sobrepasa
el tiempo de cómputo, el valor del speedup es menor que el valor de
,
sin embargo en muchos problemas donde el balanceo de carga no es perfecto y la comunicación entre procesos sobrepasa
el tiempo de cómputo, el valor del speedup es menor que el valor de ![]() . La mejor solución es la que se acerque más
al valor de
. La mejor solución es la que se acerque más
al valor de ![]()
Lenguajes de programación paralela
Existen varios lenguajes de programación paralela, sobresaliendo de estos MPI(Message Passing Interface) y PVM(Parallel Virtual Machine),
por ser uno de los estándares más aceptados.
MPI
MPI consiste de una biblioteca estándar para programación paralela en el modelo de intercambio de mensajes.
En este estándar se han incluido los aspectos más relevantes de otras bibliotecas de programación paralela.
Entre las ventajas de MPI se encuentra la disponibilidad de varios modos de comunicación, los cuales permiten
al programador el uso de buffers para el envío rápido de mensajes cortos, la sincronización de procesos o el traslape
de procesos de cómputo con procesos de comunicación. Esto último reduce el tiempo de ejecución de un programa paralelo,
pero tiene la desventaja de que el programador debe ser más cuidadoso para evitar la corrupción de mensajes.
Dos de las principales distribuciones libres de MPI son: LAM/MPI y MPICH.
PVM
PVM se comenzó a desarrollar en el verano de 1989 por el Oak Ridge National Laboratory, y posteriormente junto con
la Universidad de Tennessee en los EUA. Es una biblioteca de envío de mensajes, totalmente libre, capaz de trabajar
en redes homogéneas y heterogéneas, y que hace uso de los recursos existentes en algún centro de trabajo para poder
construir una máquina paralela de bajo costo, obteniendo su mejor rendimiento en ``horas muertas''.
Maneja transparentemente el ruteo de todos los mensajes, conversión de datos y calendarización
de tareas a través de una red de arquitecturas incompatibles. Está diseñado para conjuntar
recursos de cómputo y proveer a los usuarios de una plataforma paralela para correr sus aplicaciones,
independientemente del número de computadoras distintas que utilicen y donde éstas se encuentren
localizadas. El modelo computacional de PVM es simple y además muy general. El usuario escribe su
aplicación como una colección de tareas cooperativas. Las tareas acceden los recursos de PVM a través
de una biblioteca de rutinas. Estas rutinas permiten la inicialización y terminación de tareas a
través de la red, así como la comunicación y sincronización entre tareas.
Los constructores de comunicación incluyen aquellos para envío y recepción de estructuras de datos así como primitivas de alto nivel, tales como emisión, barreras de sincronización y sumas globales.
Tipos y modelos de clusters
En esta sección se analizan los tipos y modelos de cluster basados en la taxonomía de Flynn.
Arquitecturas de computadoras
En 1966 Michael Flynn propuso un mecanismo de clasificación de las computadoras. La taxonomía de Flynn es la manera clásica de organizar las computadoras, y aunque no cubre todas las posibles arquitecturas, proporciona una importante visión para varias de éstas.
El método de Flynn se basa en el número de instrucciones y de la secuencia de datos que la computadora utiliza para procesar información. Puede haber secuencias de instrucciones sencillas o múltiples y secuencias de datos sencillas o múltiples. Dicha clasificación da lugar a cuatro tipos de computadoras (figura ![[*]](crossref.png) ):
):
- SISD : Single Instruction Single Data
- SIMD : Single Instruction Multiple Data
- MIMD : Multiple Instruction Multiple Data
- MISD : Multiple Instruction Single Data
Los modelos SIMD y MIMD son los únicos modelos aplicables a las computadoras paralelas. También hay que mencionar que el modelo MISD es teórico.
![\includegraphics[scale=0.8]{Chapter-2/Figures/taxonomiaflynn}](img13.png)
SISD
SISD es el modelo tradicional de computadora secuencial donde una unidad de procesamiento recibe una sola secuencia de instrucciones que opera en una secuencia de datos, ejemplo: para procesar la suma de N números
![]() , el procesador necesita acceder a memoria
, el procesador necesita acceder a memoria ![]() veces consecutivas (para recibir un número). También son ejecutadas en
secuencia N-1 sumas, es decir los algoritmos para las computadoras SISD no contienen ningún paralelismo, éstas están
construidas de un solo procesador (figura ).
veces consecutivas (para recibir un número). También son ejecutadas en
secuencia N-1 sumas, es decir los algoritmos para las computadoras SISD no contienen ningún paralelismo, éstas están
construidas de un solo procesador (figura ).
SIMD
A diferencia de SISD, en el modelo SIMD se tienen múltiples procesadores que sincronizadamente ejecutan la misma secuencia de instrucciones, pero en diferentes datos (figura ). El tipo de memoria que estos sistemas utilizan es distribuida,
ejemplo: aquí hay ![]() secuencias de datos, una por procesador, por lo que diferentes datos pueden ser utilizados en
cada procesador. Los procesadores operan sincronizadamente y un reloj global se utiliza para asegurar esta operación,
es decir, en cada paso todos los procesadores ejecutan la misma instrucción, cada uno con diferente dato, ejemplo:
sumando dos matrices
secuencias de datos, una por procesador, por lo que diferentes datos pueden ser utilizados en
cada procesador. Los procesadores operan sincronizadamente y un reloj global se utiliza para asegurar esta operación,
es decir, en cada paso todos los procesadores ejecutan la misma instrucción, cada uno con diferente dato, ejemplo:
sumando dos matrices ![]() , siendo
, siendo ![]() y
y ![]() de orden 2 y teniendo 4 procesadores.
de orden 2 y teniendo 4 procesadores.
[fontfamily=courier,fontshape=it,fontsize=\small,baselinestretch=0.5] A11 + B11 = C11 , A12 + B12 = C12 A21 + B21 = C21 , A22 + B22 = C22
La misma instrucción se ejecuta en los 4 procesadores (sumando dos números) y los 4 ejecutan las instrucciones
simultáneamente. Esto toma un paso en comparación con cuatro pasos en máquina secuencial.
![\includegraphics[scale=0.8]{Chapter-2/Figures/ModeloSIMD}](img19.png)
Máquinas con arreglos de procesadores vectoriales como CRAY1 y CRAY2 son ejemplos de arquitecturas SIMD.
MIMD
El modelo MIMD es del tipo de computadoras paralelas al igual que las SIMD. La diferencia con estos sistemas
es que MIMD es asíncrono: no tiene un reloj central (figura ).
Cada procesador en un sistema MIMD puede ejecutar su propia secuencia de instrucciones y tener sus propios datos: esta
característica es la más general y poderosa de esta clasificación.
![\includegraphics[scale=0.8]{Chapter-2/Figures/ModeloMIMD}](img20.png)
Se tienen ![]() procesadores,
procesadores, ![]() secuencias de instrucciones y
secuencias de instrucciones y ![]() secuencias de datos. Cada procesador opera bajo el control de una secuencia de instrucciones, ejecutada por su propia unidad de control, es decir cada procesador es capaz de ejecutar su propio programa con diferentes datos. Esto significa que los procesadores operan asincrónicamente, o en términos simples, pueden estar haciendo diferentes cosas en diferentes datos al mismo tiempo.
secuencias de datos. Cada procesador opera bajo el control de una secuencia de instrucciones, ejecutada por su propia unidad de control, es decir cada procesador es capaz de ejecutar su propio programa con diferentes datos. Esto significa que los procesadores operan asincrónicamente, o en términos simples, pueden estar haciendo diferentes cosas en diferentes datos al mismo tiempo.
Los sistemas MIMD también tienen una subclasificación:
- Sistemas de memoria compartida:
En este tipo de sistemas cada procesador tiene acceso a toda la memoria, es decir, hay un espacio de direccionamiento compartido (figura
). Con esto se tiene tiempo de acceso a memoria uniformes, ya que todos los procesadores se encuentran igualmente comunicados con memoria principal, además el acceso a memoria es por medio de un solo canal. En esta configuración debe asegurarse que los procesadores no tengan acceso simultáneamente a regiones de memoria de una manera en la que pueda ocurrir algún error.
Ventajas:
- Facilidad de la programación. Es mucho más fácil programar en estos sistemas que en sistemas de memoria distribuida.
- Las computadoras MIMD con memoria compartida son sistemas conocidos como de multiprocesamiento simétrico (SMP), donde múltiples procesadores comparten un mismo sistema operativo y memoria. Otro término con que se conoce es máquinas firmemente juntas o de multiprocesadores.
Desventajas:
- El acceso simultáneo a memoria es un problema.
- Poca escalabilidad de procesadores, debido a que se puede generar un cuello de botella en el número de CPU.
- En computadoras vectoriales como la Cray, todas las CPU tienen un camino libre a la memoria. No hay diferencia entre las CPU.
- La razón principal por el alto precio de Cray es la memoria.
Algunos ejemplos de estos sistemas son: SGI/Cray Power Challenge, SGI/Cray C90, SGI/Onyx, ENCORE, MULTIMAX, SEQUENT y BALANCE, entre otras.
- Sistemas de memoria distribuida:
Estos sistemas tienen su propia memoria local. Los procesadores pueden compartir información solamente enviando mensajes, es decir, si un procesador requiere los datos contenidos en la memoria de otro procesador, deberá enviar un mensaje solicitándolos (figura
). A esta comunicación se le conoce como paso de mensajes.
Ventajas:
- La escalabilidad. Las computadoras con sistemas de memoria distribuida son fáciles de escalar, debido a la demanda de los recursos se puede agregar más memoria y procesadores.
Desventajas:
- El acceso remoto a memoria es lento.
- La programación puede ser complicada.
Las computadoras MIMD de memoria distribuida son conocidas como sistemas de procesamiento en paralelo (MPP), donde múltiples procesadores trabajan en diferentes partes de un programa, usando su propio sistema y memoria. También se les llama multicomputadoras, máquinas libremente juntas o cluster.
![\includegraphics[scale=0.8]{Chapter-2/Figures/SistMemCompartida}](img21.png)
![\includegraphics[scale=0.8]{Chapter-2/Figures/SistMemDistribuida}](img22.png)
MISD
El modelo MISD no tiene una aplicación real, pero se hace la descripción teórica. En este modelo, secuencias de instrucciones pasan a través de múltiples procesadores. Diferentes operaciones son realizadas en diversos procesadores, es decir, ![]() procesadores, cada uno con su propia unidad de control, comparten una memoria común (figura ).
procesadores, cada uno con su propia unidad de control, comparten una memoria común (figura ).
![\includegraphics[scale=0.8]{Chapter-2/Figures/MISD}](img23.png)
Aquí hay ![]() secuencias de instrucciones y una secuencia de datos. El paralelismo es alcanzado dejando que los procesadores realicen cosas al mismo tiempo en el mismo dato.
secuencias de instrucciones y una secuencia de datos. El paralelismo es alcanzado dejando que los procesadores realicen cosas al mismo tiempo en el mismo dato.
Tipos de clusters
Los clusters se pueden clasificar tomando en cuenta diferentes aspectos como la aplicación, disponibilidad, servicio, hardware, sistema operativo, configuración y el número de nodos.
Para cuestiones prácticas, en este trabajo se tomó en cuenta la siguiente clasificación con respecto al servicio que proveen los cluster:
- Tolerante a fallas (Fail-Over): Utiliza una conexión de alto desempeño entre las computadoras; ésta conexión es utilizada para monitorear cuál(es) de los servicios están en uso, así como la sustitución de una máquina por otra cuando uno de sus servicios ha caído.
- Balanceo de carga (Load-Balancing): Cuando los recursos del nodo son insuficientes para el procesamiento de los datos, el cluster distribuye entre los demás nodos las tareas para un mejor desempeño.
- Alto Desempeño (High Performance Computing): Estas máquinas han estado configuradas especialmente para centros de datos que requieren una potencia de computación extrema.
Modelos de clusters
- NUMA (Non-Uniform Memory Access): Tiene acceso compartido a la memoria donde se puede ejecutar el código del programa.
- MPI (Message Passing Interface): Es el estándar abierto de librerías de paso de mensajes. MPICH y LAM (Local Area Multicomputer) son dos implementaciones de MPI de código abierto.
- PVM (Parallel Virtual Machine): Al igual que MPI, también es usado en clusters Beowulf y se basa en paso de mensajes, aunque ya está cayendo en desuso, pues carece de varias características y no cumple con los nuevos estándares para desarrollo de programas paralelos.
- Beowulf: Es un cluster de componentes commodity dedicados a la solución de un problema paralelo. El primer cluster de este tipo fue desarrollado por Thomas Sterling, de la división de Ciencias de la Tierra de la NASA en JPL California. Esta solución popular ha sido ampliamente aceptada en varios ambientes de producción, principalmente laboratorios de investigación y sitios académicos.
En una configuración tradicional de un cluster Beowulf, los nodos se conectan por medio de una red privada, y sólo el nodo maestro es visible desde el exterior. El nodo maestro está reservado para acceder, compilar y manejar las aplicaciones a ejecutar.
OpenMosix como un cluster de alto desempeño y balanceo de carga
En la sección 2.3 se ha hablado de los tipos y modelos de clusters. Aquí describiremos las características de OpenMosix para entender su funcionamiento y la utilidad de éste.
OpenMosix es un parche (patch) al kernel de Linux que proporciona compatibilidad con el estándar de Linux versión 2.4.x para plataformas IA32 [MCatalan04], el algoritmo interno de balanceo de carga migra los procesos entre los nodos del cluster de forma transparente para el usuario. La principal ventaja es una mejor compartición de los recursos entre nodos, así como un mejor aprovechamiento de los mismos.
El cluster OpenMosix asigna por sí mismo la utilización óptima de los recursos que son necesarios en cada momento y de forma automática, y a esto nos referimos cuando decimos que el balanceo de carga es transparente al usuario, pues éste no necesita preocuparse por hacer uso de algunas tareas o herramientas extra para poder trabajar en este sistema.
Los algoritmos de OpenMosix son dinámicos, lo que contrasta y es una fuerte ventaja frente a los algoritmos estáticos de PVM/MPI. Responde a las variaciones en el uso de los recursos entre los nodos, migrando procesos de un nodo a otro, con
y de forma transparente para el proceso para balanceo de carga y para evitar falta de memoria en un nodo, no necesita una adaptación de la aplicación, ni siquiera que el usuario sepa algo sobre el cluster.
OpenMosix puede balancear una única aplicación, si esta está dividida en procesos. Esto ocurre en gran número de
aplicaciones hoy en día: lo que balancea son procesos. Cuando un nodo está muy cargado por sus procesos y otro no,
se migran procesos del primer nodo al segundo.
La característica de migración de procesos transparente hace que el cluster funcione de forma ``similar'' a un sistema SMP(Symmetric Multi Processing), donde las tareas originadas en un nodo del cluster pueden distribuirse en los diferentes ``procesadores'' de este sistema.
El proyecto OpenMosix está respaldado y siendo desarrollado por personas muy competentes y respetadas en el mundo del Open Source, trabajando juntas en todo el mundo, tratando de crear un estándar en el entorno de clustering para todo tipo de aplicaciones HPC (High Performance Computing).
Características de OpenMosix
Pros de OpenMosix:
- No se requieren paquetes extra.
- No son necesarias modificaciones en el código.
Contras de OpenMosix:
- Es dependiente del kernel.
- No migra todos los procesos siempre, tiene limitaciones de funcionamiento.
- Problemas con memoria compartida.
Además los procesos con múltiples threads (hilos) no ganan demasiada eficiencia.
Tampoco se obtiene mucha mejora cuando se ejecuta un solo proceso, como por ejemplo un navegador web.
Subsistemas de OpenMosix
Actualmente podemos dividir los parches de OpenMosix en cuatro grandes subsistemas.
- Mosix File System (MFS):
En cuanto a líneas de código el primer subsistema es MFS que permite un acceso a sistemas de archivos remotos, por ejemplo, como si estuviese localmente montado.
El sistema de archivos del nodo raíz y de los demás podrán ser montados en el directorio
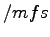 y se podrán acceder por ejemplo: para acceder al
y se podrán acceder por ejemplo: para acceder al 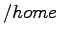 del nodo 2 dentro del directorio
del nodo 2 dentro del directorio
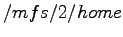 desde cualquier nodo del cluster.
desde cualquier nodo del cluster.
- Migración de procesos:
Con OpenMosix se puede lanzar un proceso en una computadora y ver si se ejecuta en ésta, en otra, o en el seno del cluster (nodo maestro).
Cada proceso tiene su único nodo raíz (UHN, Unique Home Node) que corresponde con el que lo ha generado.
El concepto de migración significa que un proceso se divide en dos partes: la parte del usuario y la del sistema. La parte, o área de usuario, será movida al nodo remoto mientras el área de sistema espera en el raíz. Mientras tanto OpenMosix se encarga de establecer la comunicación entre estos dos procesos.
- Direct File System Access(DFSA):
OpenMosix proporciona MFS con la opción DFSA, que permite acceso a todos los sistemas de archivos tanto locales como remotos.
- Memory Ushering:
Este subsistema se encarga de migrar las tareas que superan la memoria disponible en el nodo en el que se ejecutan. Las tareas que separan dicho límite se migran forzosamente a un nodo destino de entre los nodos del cluster que tengan suficiente memoria como para ejecutar el proceso sin necesidad de hacer swap a disco, ahorrando así la gran pérdida de rendimiento que esto supone.
El subsistema de memoria ushering es un subsistema independiente del subsistema de equilibrado de carga, y por ello se le considera por separado.
El algoritmo de migración
El proceso de migración basado en el modelo
![]() , en el que puede migrarse cualquier proceso a cualquier nodo del cluster de forma completamente transparente. La migración también puede ser automática: el algoritmo que lo implementa tiene una complejidad del orden de
, en el que puede migrarse cualquier proceso a cualquier nodo del cluster de forma completamente transparente. La migración también puede ser automática: el algoritmo que lo implementa tiene una complejidad del orden de ![]() , siendo
, siendo ![]() el número de nodos del cluster [MCatalan04].
el número de nodos del cluster [MCatalan04].
La ventaja del modelo es que la distribución de tareas en el cluster está determinada por OpenMosix de forma dinámica, conforme se van creando tareas. Así, cuando un nodo está demasiado cargado y las tareas que se están ejecutando puedan migrar a cualquier otro nodo del cluster. Es así como desde que una tarea se ejecuta hasta que ésta termina, podrá migrar de un nodo a otro, sin que el proceso sufra mayores cambios.
El nodo raíz:
Cada proceso ejecutado en el cluster tiene asignado un único nodo raíz, en el cual se lanza originalmente el proceso y donde éste empieza a ejecutarse.
Desde el punto de vista del espacio de procesos de la maquina del cluster, cada proceso con su correspondiente Identificador de Proceso (PID) parece ejecutarse en su nodo raíz. El nodo de ejecución puede ser el nodo raíz u otro diferente, hecho que da lugar a que el proceso no use un PID del nodo de ejecución si no que el proceso migrado se ejecutara en este como una ![]() (hebra o hilo) del kernel. La interacción con un proceso, por ejemplo enviarle señales a cualquier proceso migrado, se puede realizar exclusivamente del nodo raíz.
(hebra o hilo) del kernel. La interacción con un proceso, por ejemplo enviarle señales a cualquier proceso migrado, se puede realizar exclusivamente del nodo raíz.
Por otra parte la migración y el retorno al nodo raíz de un proceso se puede realizar tanto desde el nodo raíz como desde el nodo dónde se ejecuta el proceso. Esta tarea la puede llevar el administrador de cualquiera de los dos sistemas.
El mecanismo de migrado
La migración de procesos en OpenMosix es completamente transparente. Esto significa que al proceso migrado no se le avisa que ya no se ejecuta en su nodo de origen, y si tuviera que leer o escribir algo, lo haría en el nodo origen, hecho que supone leer o grabar remotamente en este nodo.
¿Cúando podrá migrar un proceso?
Desgraciadamente, no todos los procesos pueden migrar en cualquier circunstancia. El mecanismo de migración de procesos puede operar sobre cualquier tarea de un nodo sobre el que se cumplen algunas condiciones predeterminadas, estas son:
- El proceso no puede ejecutarse en modo de emulación VM86 (Modo Virtual 8086), donde se requieren ejecutar instrucciones antiguas para procesadores de arquitectura 8086.
- El proceso no puede ejecutar instrucciones en ensamblador propias de la máquina donde se lanza y que no tiene la máquina destino (en un cluster heterogéneo).
- El proceso no puede mapear memoria de un dispositivo a la RAM, ni acceder directamente a los registros de un dispositivo.
- Y una condición muy importante: el proceso no puede usar segmentos de memoria compartida.
Cumpliendo todas estas condiciones el proceso puede migrar y ejecutarse migrado. Como se puede sospechar OpenMosix no sabe nada de esto y en un principio migra todos los procesos que puedan hacerlo si por el momento cumple todas las condiciones, y en caso de que algún proceso deje de cumplirlas, lo devuelve al nodo raíz para que se ejecute en él mientras no pueda migrar de nuevo.
Comunicación entre las dos áreas
Un aspecto interesante es cómo se realiza la comunicación entre el área de usuario y el área de kernel.
En algún momento, el proceso migrado puede necesitar hacer alguna llamada al sistema. Esta llamada se captura y se evalúa:
- Si puede ser ejecutada al nodo al que la tarea ha migrado, o
- Si necesita ser lanzada en el nodo raíz del proceso migrado
Si la llamada puede ser lanzada al nodo donde la tarea migrada se ejecuta, los accesos al kernel se hacen de
forma local, es decir, que se atiende en el nodo donde la tarea se ejecuta sin ninguna carga adicional a la red.
Por desgracia, las llamadas más comunes son las que se han de ejecutar forzosamente al nodo raíz, puesto
que se comunican con el hardware. Es el caso, por ejemplo, de una lectura o una escritura a disco. En este caso el
subsistema de OpenMosix del nodo donde se ejecuta la tarea contacta con el subsistema de OpenMosix del nodo
raíz. Para enviarle la petición, así como todos los parámetros y los datos del nodo raíz que necesitara procesar.
El nodo raíz procesará la llamada y enviara de vuelta al nodo dónde se esta ejecutando realmente el proceso migrado cualquiera de estos datos:
- El valor del éxito o fracaso de la llamada.
- Aquello que necesite saber para actualizar sus segmentos de datos.
- El estado en el que estará si el proceso se ejecuta en el nodo raíz.
Esta comunicación también puede ser generada por el nodo raíz. Es el caso, por ejemplo, del envió de una
señal. El subsistema de OpenMosix del nodo raíz contacta con el subsistema de OpenMosix del nodo dónde el
proceso migrado se ejecuta, y él avisa que ha ocurrido un evento asíncrono. El subsistema de OpenMosix del nodo
dónde el proceso migrado se ejecuta parará el proceso migrado y el nodo raíz podrá empezar a atender el código
del área del kernel que corresponderá a la señal asíncrona.
Finalmente, una vez realizada toda la operación necesaria del área del kernel, el subsistema de
OpenMosix del nodo raíz del proceso envía al nodo donde está ejecutándose realmente el proceso migrado, el
aviso detallado de la llamada y todo aquello que el proceso necesita saber (anteriormente enumerado) cuando
recibió la señal, y el proceso migrado finalmente recuperará el control.
Por todo esto el proceso migrado es como si estuviera al nodo raíz y hubiera recibido la señal de éste.
Tenemos un escenario muy simple donde el proceso se suspende esperando un recurso. Recordemos que la
suspensión esperando un recurso se produce únicamente en área de kernel. Cuando se pide una página de disco o
se espera un paquete de red se resuelve como en el primer caso comentado, es decir, como una llamada al kernel.
Este mecanismo de comunicación entre áreas es el que nos aseguran que:
- La migración sea completamente transparente tanto para el proceso que migra como para los procesos que cohabiten con el nodo raíz.
- Que el proceso no necesite ser reescrito para poder migrar, ni sea necesario conocer la topología del cluster para escribir una aplicación paralela.
No obstante, en el caso de llamadas al kernel que tengan que ser enviadas forzosamente al nodo raíz, tendremos una sobrecarga adicional a la red debida a la transmisión constante de las llamadas al kernel y la recepción de sus valores de vuelta.
Destacamos especialmente esta sobrecarga en el acceso a sockets y el acceso a disco duro, que son las dos
operaciones mas importantes que se habrán de ejecutar en el nodo raíz y suponen una sobrecarga al proceso de comunicación entre la área de usuario migrada y la área de kernel del proceso migrado.
Siguiente: Análisis para el diseño Subir: Implementación de un cluster Anterior: Antecedentes
Licencia: Creative Commons

Reconocimiento-NoComercial 2.5 México
JoseCC & SuperBenja, 2006-06-08